Now that we’ve discussed central tendency, dispersion, and probability, we need to talk about sampling. As mentioned earlier, we cannot often observe an entire population for various reasons, and we need to rely on (hopefully random and representative) samples. So, when we sample a population, what can we say?
The sample mean (\(\overline{y}\)) is our best guess for the population mean (\(\mu\))
The sample st. dev. (\(s\)) is our best guess for the population st. dev. (\(\sigma\))
Sampling
Suppose we are interested in sampling School Expenditures and Test Scores for the 50 States from school year 1994-95. Specifically, we are interested in average teacher salary. However, for one reason or another, we cannot observe all 50 states at once though we can look at a sample of 10 states.
Code
usa <-read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/stevedata/Guber99.csv")mu <-mean(usa$tsalary) # calculate "true" mean
Central Limit Theorem
At this point, you have pulled at least one combination of 10 random states out of 50 total states. There are 62.8 billion different combinations of 10 states that we can pull out of the 50, and each sample we draw is going to be a little bit different. Well, if each sample is different, then what can we say about the distribution of these sample means?
This might seem like an odd question, but it is an important one.
Due to the Central Limit Theorem, we know that the distribution of sample means is approximately normal.In other words, if we take 10,000 random samples of 10, and calculate the mean of each sample (call it \(\overline{y}_i\)), the distribution of the \(\overline{y}_i\)s will be normally distributed.
Moreover, the mean of the distribution of \(\overline{y}_i\)s has the same mean as the original population distribution (\(\mu\)). Also, the standard deviation of the \(\overline{y}_i\)s is equal to \(\frac{\sigma}{\sqrt{n}}\). We call \(\frac{\sigma}{\sqrt{n}}\) the standard error of the sample mean.
Central Limit Theorem
Below is a numerical demonstration of the Central Limit Theorem.
This code samples 10 data points from the total of 50, and then calculates an average. However, since it is inside of a loop, the sampling and averaging is repeated over and over. The code keeps track of the calculated means in the vector meanz so we can examine the distribution.
Central Limit Theorem
The mean of this distribution should be approximately the same as the population mean.
In addition, the standard deviation of this distribution should be approximately equal to \(\frac{\sigma}{\sqrt{n}}\).
It’s important to note that we do not know anything about the distribution of teacher salaries in the data. The distribution can be any arbitrary shape, and the CLT will still apply. In other words, it’s true for any distribution that the mean of the sample means equals the population mean, and the standard deviation of the sample means is equal to the standard deviation of the original distribution divided by the square root of the sample size.
Central Limit Theorem
What happens if we change the number of samples, or change the size of the samples? Below, I created a function to do CLT simulations like what I’ve done above. These functions allow you to change both the number of samples and the size of the samples. Try tweaking some of the following code in the WebR chunk.
Clearly, the distribution gets tighter (taller and skinnier) around the true mean as \(n\) increases. In other words, the sample average will be more accurate as \(n\) increases. This is why large samples can be helpful!
Teacher Salaries
Now, let’s return to the initial idea – we want to calculate out the average salary of teachers in the US. Below, I will do one last sampling that we will use for the remainder of the notes.
Code
set.seed(123)smpl <-sample(1:50, 10, TRUE) # 10 random draws from 1:50 *with* replacement.mydata <- usa$tsalary[smpl]cat(mydata, "\n")cat("Mean of 10 Random Draws:", mean(mydata))
Output
28.493 31.511 36.785 32.175 32.477 31.285 31.223 38.555 36.785 31.189
Mean of 10 Random Draws: 33.0478
Teacher Salaries
As mentioned before, we were only able to sample 10 states out of 50, and we said that our sample average (\(\overline{y}\)) is our best guess of the population average (\(\mu\)). However, best\(\neq\) good. It is not believable that \(\overline{y} = \mu\), but rather \(\overline{y} \approx \mu\).
To adjust for the uncertainty associated with sampling, we need to produce a range of values instead of just one. For example, maybe we want to give a range like \(33.0478 \pm 5\). However, this is not all that satisfying as we’re just pulling \(5\) out of thin air.To justify the size of our range, we are going to lean on the CLT. The range we create is going to be called a confidence interval.
Teacher Salaries
To start, we need to come up with a middle point for our interval. Since \(\overline{y}\), or 33.0478 in this case, is our best guess, it is natural to use it as the center.
Next, we need to come up with how wide to make our interval. The width of our confidence interval is going to depend on two things:
The standard error of the sample mean (\(\frac{s}{\sqrt{n}}\)).
The level of confidence you select, represented by \(z\).
The first part is easy. Once you gather your data, calculate the standard deviation and divide by the square root of the sample size. In this case, our standard deviation is 3.2033078 and sample size is 10. Therefore, the standard error is 1.0129749.
Teacher Salaries
How do we select our level of confidence, and what does it do to the width of our interval? First, larger levels of confidence require larger intervals.Think of it this way: if you want to be 100% confident that \(\mu\) is within your interval, your interval better be \(-\infty\) to \(+\infty\)! Otherwise, you could be wrong, in theory.However, if you’re willing to be wrong just 1% of the time, and you lower your confidence to 99%, you can shrink that interval a bit. So, as confidence intervals get smaller, so does your level of confidence that \(\mu\) exists within your interval.
Since sample means come from a normal distribution (thanks to the CLT), we can use values from the standard normal distribution to determine confidence levels (or probabilities). For example, we know that 95.45% of draws will be between -2 and +2, or \(\pm 2\). To get exactly 95%, we would use \(\pm 1.96\).
\(z\)-values for other confidence levels can be found via the following R code: qnorm((1 - 0.95)/2), where you’d replace 0.95 with 0.90, 0.99, or whatever confidence level you’d like. However, 90%, 95%, and 99% are the most frequently used.
Teacher Salaries
At this point, we have everything we need to create our confidence interval! The formula is as follows:
\[\overline{y} \pm (z\times\frac{s}{\sqrt{n}})\]
For teacher salaries, our confidence interval, numerically, is:
Of course, you might ask: does this work? Since we know \(\mu\) (because it is in our data), we can compare this interval with \(\mu\). We calculated \(\mu\) as mean(usa$tsalary): 34.82892, and this is indeed within our interval.
Teacher Salaries
We’ve now seen some of the power of the CLT – without observing the entire dataset, we can still get precise estimates of population parameters. The CLT is incredibly important in the field of statistics, and basically makes the rest of this course possible.
Next, we are going to use the CLT to help us perform hypothesis tests.
Heart Medication
Suppose we are working for a large pharma company. This company has recently released a new drug that they think will increase heart rates. This is our hypothesis. To test this, we are going to do the following:
To start, we will measure the heart rates (\(\text{HR}\)) of 100 individuals as a baseline.
We’ll then give these 100 individuals the heart medicine, and re-measure their heart rate.
For each person, we will calculate the change in their heart rate.
From now on, the data I will use is \(\text{HR}_{\text{drug}} - \text{HR}_{\text{baseline}}\), the mean of which is \(\hat{y}\)
Heart Medication
Now, if we assume that our drug does not work, we would expect \(\mu = 0\) and \(\hat{y} \approx 0\). In English, heart rates should not increase if the drug is ineffective. Essentially, we are going to make a confidence interval around 0. Then, if we find \(\hat{y}\) is outside of that confidence interval, we can reject the idea/assumption/hypothesis that the drug is ineffective.1
If \(\hat{y}\) is inside the null hypothesis’s confidence interval, we say we reject the null. In other words, we have found evidence to rule out the null hypothesis. Be careful: evidence \(\neq\) proof.
If \(\hat{y}\) is outside the null hypothesis’s confidence interval, we say we fail to reject the null. In other words, we have not found strong enough evidence to rule out the null. We never say that we accept the null hypothesis. Why the double negative? In statistics, the absence of evidence is not evidence of absence.
Heart Medication
The next step would be to construct this confidence interval around zero. We need three things:
A center for the interval. This one is easy: it’s zero
A confidence level. This one is arbitrary: let’s use 95%, or \(z = 1.96\)
A standard error. This one is calculable: \(\frac{s}{\sqrt{n}}\)
Once we construct our interval, we must come up with critical values. This is just a fancy term for the edges of our confidence interval. Here, the critical values are:.
Finally, if \(|\sqrt{n} \times \frac{\hat{y}}{s}| > |(1.96 \times \frac{s}{\sqrt{n}})|\), or in words, the magnitude of the test statistic is greater than the magnitude of the critical value, we can reject the null. Otherwise, we fail to reject the null.
Heart Medication
Let’s simulate some data and see what happens. Assume the baseline heart rate average is 80 beats per minute and the “drugged” heart rate is 82 beats per minute. Can we say that the drug worked? Numerically, heart rates seem to have increased! However, this could just be due to random chance. We need to figure out how likely this number would be assuming the medication does not work.
Code
hr_before <-rnorm(n =100, mean =80, sd =5)hr_after <-rnorm(n =100, mean =82, sd =5)hr_diff <- hr_after - hr_beforehr_diff_mean <-mean(hr_diff)hr_diff_sd <-sd(hr_diff)hr_diff_n <-length(hr_diff)cat("Mean of Difference in Heart Rate:", hr_diff_mean, "\n")cat("St. Dev. of Difference in Heart Rate:", hr_diff_sd, "\n")cat("Sample Size of Difference in Heart Rate:", hr_diff_n)
Output
Mean of Difference in Heart Rate: 1.555863
St. Dev. of Difference in Heart Rate: 6.893514
Sample Size of Difference in Heart Rate: 100
Heart Medication
Our critical value is: \(1.96 \times \frac{s}{\sqrt{n}}\)
Our test statistic is: \(\sqrt{n} \times \frac{\hat{y}}{s}\)
Code
critical_value <-1.96* (hr_diff_sd /sqrt(hr_diff_n))test_statistic <-sqrt(hr_diff_n) * (hr_diff_mean / hr_diff_sd)cat("Critical Value:", critical_value, "\n")cat("Test Statistic:", test_statistic, "\n")if(test_statistic > critical_value){cat("Reject the Null")} else {cat("Fail to Reject the Null")}
Output
Critical Value: 1.351129
Test Statistic: 2.256995
Reject the Null
Heart Medication
Our hypothesis test suggests that we should reject the null hypothesis, or in other words, it is unlikely that the null hypothesis is true. However, comparing two numbers might not be particularly intuitive.
Below is a visualization of the entire distribution of the sample means we would expect IF the null was true. The shaded region represents where we would expect 95% of those sample means to fall. The red vertical line represents what we observed in the data.
Plot
Heart Medication
But, isn’t this entirely arbitrary? Consider the plot below. Given our previous steps, we would treat each one of these red lines the same as one another even though they’re all different distances from the critical value.
Plot
This is why statisticians came up with the idea of something called p-values.
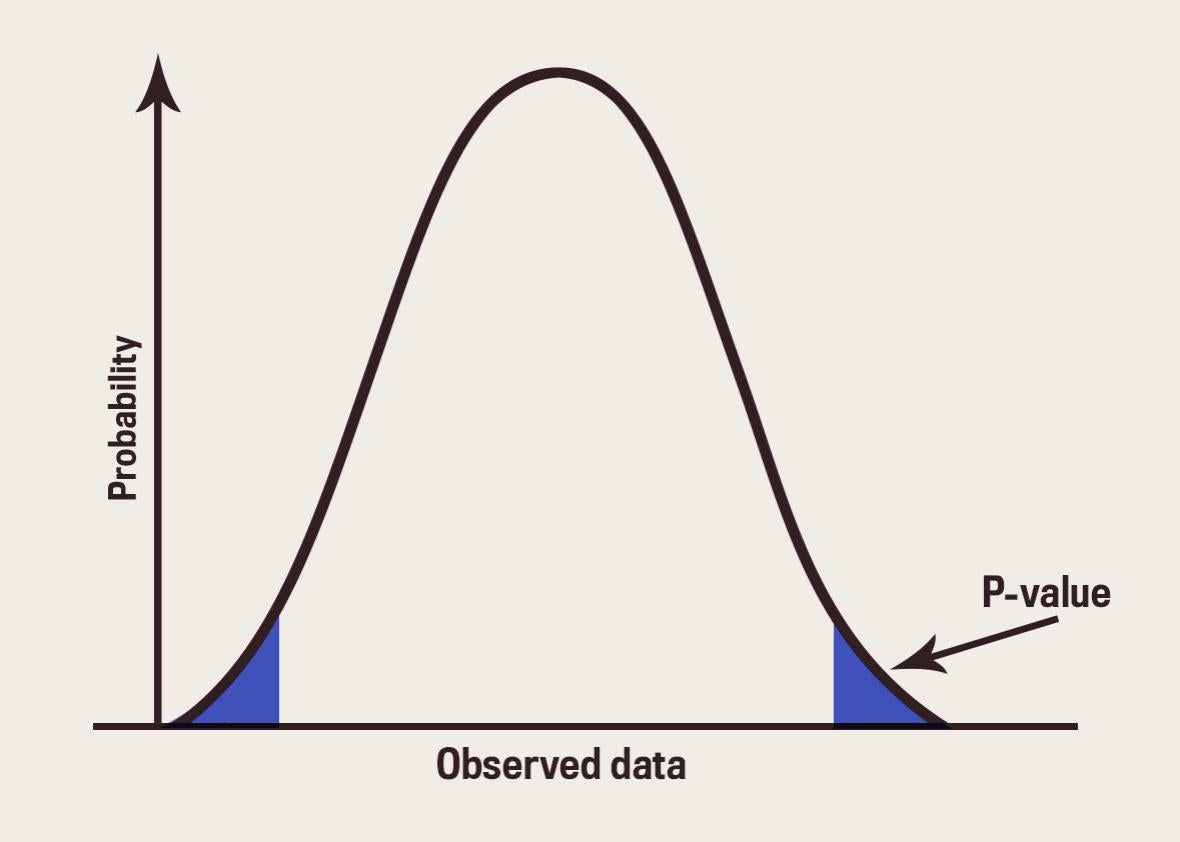
\(p\)-value
A \(p\)-value represents the probability of observing a sample value as extreme as, or more extreme than, the value observed, given the null hypothesis is true.
\(p\)-values are misinterpreted by even the most experienced researchers, and they take a lot of time to grasp. It’s a crucial concept, though, so make sure to take the time to think about this. We will be dealing with p-values (and test statistics) through out the rest of this course.
Heart Medication
To calculate a p-value, we need to figure out the probability mass to the right of the positive test statistic plus the probability mass to the left of the negative test statistic. See here for an example. Calculating one of the two ranges in R is easy. To calculate the area of both, we can just multiply by 2.
Code
2*pnorm(test_statistic, lower.tail =FALSE)
Output
[1] 0.02400836
Heart Medication
This section of the module contained a lot of statistical theory and coding. However, the point was to have you go through this so you understand deeply the concept of hypothesis testing before you were exposed to some of the shortcut functions.
Of course, R contains some handy functions for hypothesis testing. See below for some of these.
Code
# Note the output of this function.# There is a "mean", "t", and "p-value"# The "mean" and "t" are exactly equal to# what we calculated before.# The "p-value" is slightly different# but the reason is unimportant for now.# R also generates a 95% conf. interval for you.# Note, though, that this is different from what had.# Again, this is unimportant for the moment.t.test(hr_diff)cat("\n\n")# You can use the following code for the same output.# paired = TRUE effectively differences the data for you.# Note, I am changing the confidence level to 99%t.test(hr_after, hr_before, paired =TRUE, conf.level =0.99)cat("\n\n")# You can also compare two independent samples# These can even have different sample sizes.# For example, a prof might want to know if# two classes scored statistically differently on# on an exam. This would be how to do that.# Everything would be interpreted in the same way.# You might notice that some of the output is different# when doing the analysis this way.t.test(hr_after, hr_before, paired =FALSE)
Output
One Sample t-test
data: hr_diff
t = 2.257, df = 99, p-value = 0.02621
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.1880402 2.9236858
sample estimates:
mean of x
1.555863
Paired t-test
data: hr_after and hr_before
t = 2.257, df = 99, p-value = 0.02621
alternative hypothesis: true mean difference is not equal to 0
99 percent confidence interval:
-0.2546533 3.3663794
sample estimates:
mean difference
1.555863
Welch Two Sample t-test
data: hr_after and hr_before
t = 2.3169, df = 195.66, p-value = 0.02154
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.2315098 2.8802163
sample estimates:
mean of x mean of y
81.70924 80.15337
{kind=link}
